A Simple Autoencoder



import torch
import numpy as np
from torchvision import datasets
import torchvision.transforms as transforms
# convert data to torch.FloatTensor
transform = transforms.ToTensor()
# load the training and test datasets
train_data = datasets.MNIST(root='data', train=True,
download=True, transform=transform)
test_data = datasets.MNIST(root='data', train=False,
download=True, transform=transform)
# Create training and test dataloaders
# number of subprocesses to use for data loading
num_workers = 0
# how many samples per batch to load
batch_size = 20
# prepare data loaders
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=batch_size, num_workers=num_workers)
import matplotlib.pyplot as plt
%matplotlib inline
# obtain one batch of training images
dataiter = iter(train_loader)
images, labels = dataiter.next()
images = images.numpy()
# get one image from the batch
img = np.squeeze(images[0])
fig = plt.figure(figsize = (5,5))
ax = fig.add_subplot(111)
ax.imshow(img, cmap='gray')

Linear Autoencoder
We'll train an autoencoder with these images by flattening them into 784 length vectors. The images from this dataset are already normalized such that the values are between 0 and 1. Let's start by building a simple autoencoder. The encoder and decoder should be made of one linear layer. The units that connect the encoder and decoder will be the compressed representation.
Since the images are normalized between 0 and 1, we need to use a sigmoid activation on the output layer to get values that match this input value range.
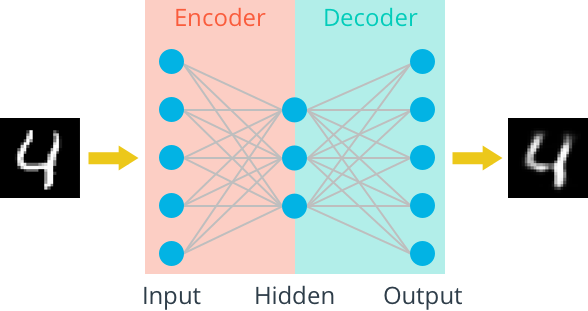
TODO: Build the graph for the autoencoder in the cell below.
The input images will be flattened into 784 length vectors. The targets are the same as the inputs. The encoder and decoder will be made of two linear layers, each. The depth dimensions should change as follows:784 inputs > encoding_dim > 784 outputs.> All layers will have ReLu activations applied except for the final output layer, which has a sigmoid activation.
The compressed representation should be a vector with dimension encoding_dim=32.
import torch.nn as nn
import torch.nn.functional as F
# define the NN architecture
class Autoencoder(nn.Module):
def __init__(self, encoding_dim):
super(Autoencoder, self).__init__()
## encoder ##
# linear layer (784 -> encoding_dim)
self.fc1 = nn.Linear(28 * 28, encoding_dim)
## decoder ##
# linear layer (encoding_dim -> input size)
self.fc2 = nn.Linear(encoding_dim, 28*28)
def forward(self, x):
# add layer, with relu activation function
x = F.relu(self.fc1(x))
# output layer (sigmoid for scaling from 0 to 1)
x = F.sigmoid(self.fc2(x))
return x
# initialize the NN
encoding_dim = 32
model = Autoencoder(encoding_dim)
print(model)
Training
Here I'll write a bit of code to train the network. I'm not too interested in validation here, so I'll just monitor the training loss and the test loss afterwards.
We are not concerned with labels in this case, just images, which we can get from the train_loader. Because we're comparing pixel values in input and output images, it will be best to use a loss that is meant for a regression task. Regression is all about comparing quantities rather than probabilistic values. So, in this case, I'll use MSELoss. And compare output images and input images as follows:
loss = criterion(outputs, images)Otherwise, this is pretty straightfoward training with PyTorch. We flatten our images, pass them into the autoencoder, and record the training loss as we go.
# specify loss function
criterion = nn.MSELoss()
# specify loss function
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# number of epochs to train the model
n_epochs = 20
for epoch in range(1, n_epochs+1):
# monitor training loss
train_loss = 0.0
###################
# train the model #
###################
for data in train_loader:
# _ stands in for labels, here
images, _ = data
# flatten images
images = images.view(images.size(0), -1)
# clear the gradients of all optimized variables
optimizer.zero_grad()
# forward pass: compute predicted outputs by passing inputs to the model
outputs = model(images)
# calculate the loss
loss = criterion(outputs, images)
# backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
# update running training loss
train_loss += loss.item()*images.size(0)
# print avg training statistics
train_loss = train_loss/len(train_loader)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(
epoch,
train_loss
))
# obtain one batch of test images
dataiter = iter(test_loader)
images, labels = dataiter.next()
images_flatten = images.view(images.size(0), -1)
# get sample outputs
output = model(images_flatten)
# prep images for display
images = images.numpy()
# output is resized into a batch of images
output = output.view(batch_size, 1, 28, 28)
# use detach when it's an output that requires_grad
output = output.detach().numpy()
# plot the first ten input images and then reconstructed images
fig, axes = plt.subplots(nrows=2, ncols=10, sharex=True, sharey=True, figsize=(25,4))
# input images on top row, reconstructions on bottom
for images, row in zip([images, output], axes):
for img, ax in zip(images, row):
ax.imshow(np.squeeze(img), cmap='gray')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
